Cache Hierarchies
- Data and instructions are stored on DRAM chips
- DRAM is a technology that has high bit density, but relatively poor latency
- an access to data in memory can take as many as 300 cycles!
- Hence, some data is stored on the processor in structure called the cache
- caches employ SRAM technology, which is faster, but has lower bit density
- Internet browsers also cache web pages – same concept
Memory Structure
- Address and data
- Address is the index, are not stored in memory
- Address can be in unit of byte or in unit of word
- Only data is stored in memory
Memory Hierarchy
- As you go further, capacity and latency increase
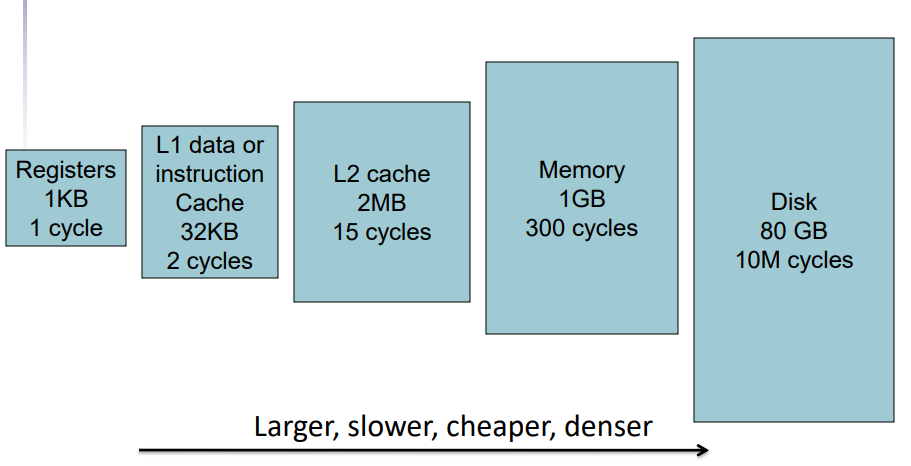
- Store everything on disk
- Copy recently accessed (and nearby) items from disk to smaller DRAM memory
- Main memory
- Copy more recently accessed (and nearby) items from DRAM to smaller SRAM memory
- Cache memory attached to CPU
Memory Hierarchy Levels
- Block (also called line): unit of copying
- May be multiple words
- The memory in upper level is originally empty
- If accessed data is absent
- Miss: block copied from lower level
- Time taken: miss penalty
- Miss ratio: misses/accesses
- If accessed data is present in upper level
- Hit: access satisfied by upper level
- Hit ratio: hits/accesses = 1 – miss ratio
- Then accessed data supplied from upper level
Locality:
- Why do caches work?
- Temporal locality: if you used some data recently, you will likely use it again
- Spatial locality: if you used some data recently, you will likely access its neighbors
Memory Technology:
- Static RAM (SRAM)
- 0.5ns – 2.5ns, $500 – $1000 per GB
- Volatile: data will lost when SRAM is not powered
- Dynamic RAM (DRAM)
- 50ns – 70ns, $10 – $20 per GB
- Flash
- 5us – 50us, $0.75-$1 per GB
- Magnetic disk
- 5ms – 20ms, $0.05 – $0.1 per GB
- Ideal memory
- Access time of SRAM
- Capacity and cost/GB of disk
SRAM Technology
DRAM Technology
Advanced DRAM Organization
Flash Storage
Disk Storage
Disk Sectors and Access
Cache Memory
Cache Memory
- Cache memory
- The level of the memory hierarchy closest to the CPU
- Given accesses X1, …, Xn–1, Xn
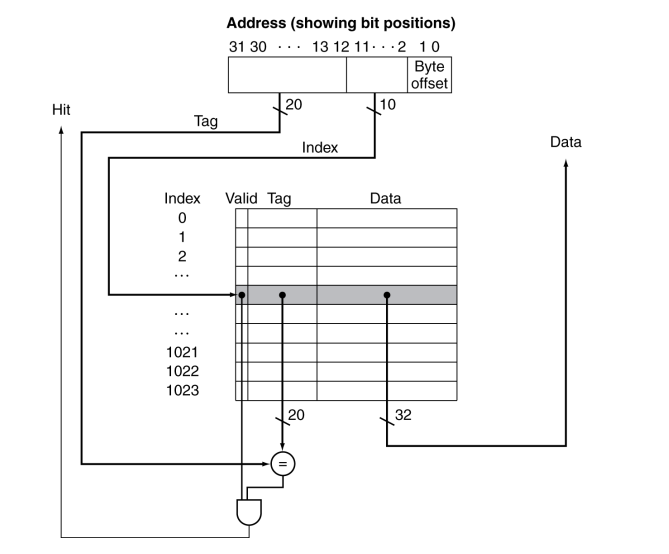
Direct Mapped Cache
- Memory size: 32 words, cache size: 8 words
- The address is in unit of word
- Direct mapper cache:
- Location determined by address
- One data in memory is mapped to only one location in cache
- The lower bits defines the address of the cache
Tags and Valid Bits
- How do we know which particular block is stored in a cache location?
- Store block address as well as the data
- Actually, only need the high-order bits
- Called the tag
- What if there is no data in a location?
- Valid bit: 1 = present, 0 = not present
- Initially 0
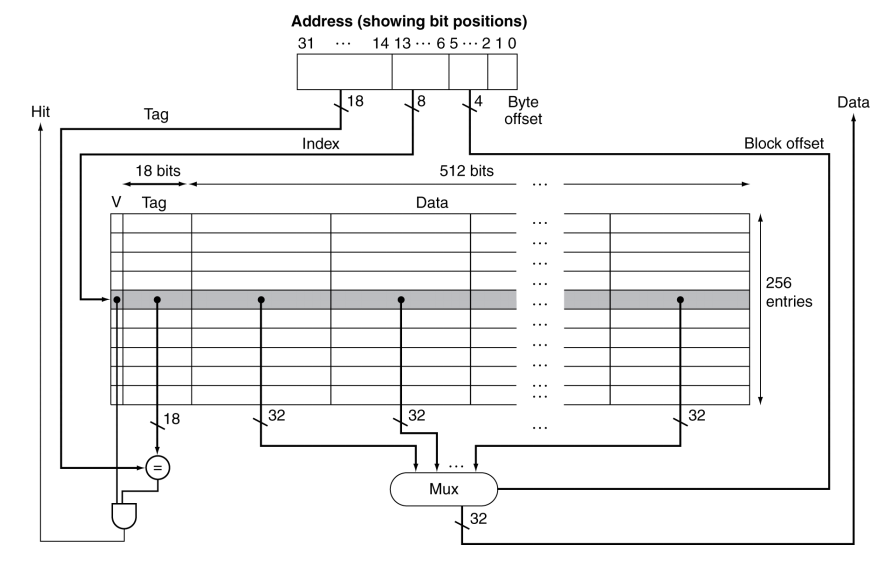
Larger Block Size:
- Assume
- 32-bit address
- Direct mapped cache
- $2^n$ number of blocks, so n bit for index
- Block size: $2^m$ words, so m bit for the word within the block
- Calculate:
- Size of tag field: 32-(n+m+2)
- Size of cache: $2^n*(\text{block size} + \text{tag size} + \text{valid field size})\ = 2n*(2m*32+(32-n-m-2)+1)$
Block Size Considerations:
Larger blocks should reduce miss rate
- Due to spatial locality
But in a fixed-sized cache
- Larger blocks => fewer of them
- More competition => increased miss rate
- Larger blocks => pollution
Larger miss penalty (with longer address bits)
Can override benefit of reduced miss rate
Early restart and critical-word-first can help
提前缓存块
先拿到需要的,再去缓存整个块
Cache Misses
- On cache hit, CPU proceeds normally
- On cache miss
- Stall the CPU pipeline
- Fetch block from next level of hierarchy
- Instruction cache miss
- Restart instruction fetch
- Data cache miss
- Complete data access
Write-Through
- On data-write hit, could just update the block in cache
- But then cache and memory would be inconsistent
- Write through: also update memory
- But makes writes take longer
- write buffer:【improve】
- Holds data waiting to be written to memory
- CPU continues immediately
- Only stalls on write if write buffer is already full
Write-Back:
- On data-write hit, just update the block in cache
- Keep track of whether each block is dirty
- When a dirty block is replaced
- Write it back to memory
- Can use a write buffer to allow replacing block to be read first
Write Allocation
What should happen on a write miss?
Alternatives for write-through
- Allocate on miss: fetch the block
- Write around: don’t fetch the block
- Since programs often write a whole block before reading it (e.g., initialization)
For write-back
- Usually fetch the block
Write Policies Summary
If that memory location is in the cache:
Send it to the cache
write-through policy: send it to memory right away
write-back policy: Wait until we kick the block out
If it is not in the cache:
- write allocate policy: Allocate the block (put it in the cache)
- no write allocate policy: Write it directly to memory without allocation