计划:
- 地址空间
- 页面硬件
xv6VM 代码
虚拟内存概述
当今的问题:
[用户/内核图]
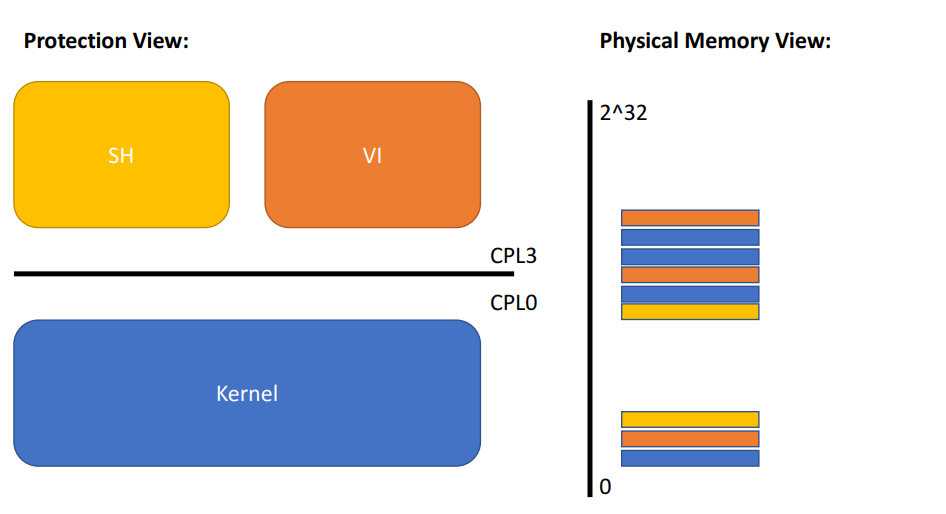
内存视图:内存中包含用户进程和内核的图表
假设shell有一个bug:有时它会写入随机存储器地址
我们如何防止它破坏内核或其他过程?
我们想要隔离的地址空间:
- 每个进程都有自己的内存
- 它可以读写自己的内存
- 它无法读取或写入任何其他内容
- 挑战:如何在一个物理内存中复用多个内存?同时保持内存之间的隔离
xv6 和 JOS 使用 x86 的分页硬件实现 AS
分页为寻址提供了间接层:

s/w 只能 ld/st到虚拟地址,而非物理地址,内核告诉MMU如何将每个虚拟地址映射到物理地址。
MMU 本质上是一个由 va 索引至 pa 的表,MMU 能够限制用户代码允许使用的虚拟地址。
x86 映射 4KB “页面”并从 4KB 边界开始对齐——因此页表索引是 VA 的前20位。
页表条目(PTE)中的内容是什么?
前20位是物理地址的前20位
- “物理页码”
- MMU用PPN取代VA的高20位
低12位是标志位
Present, Writeable,&c
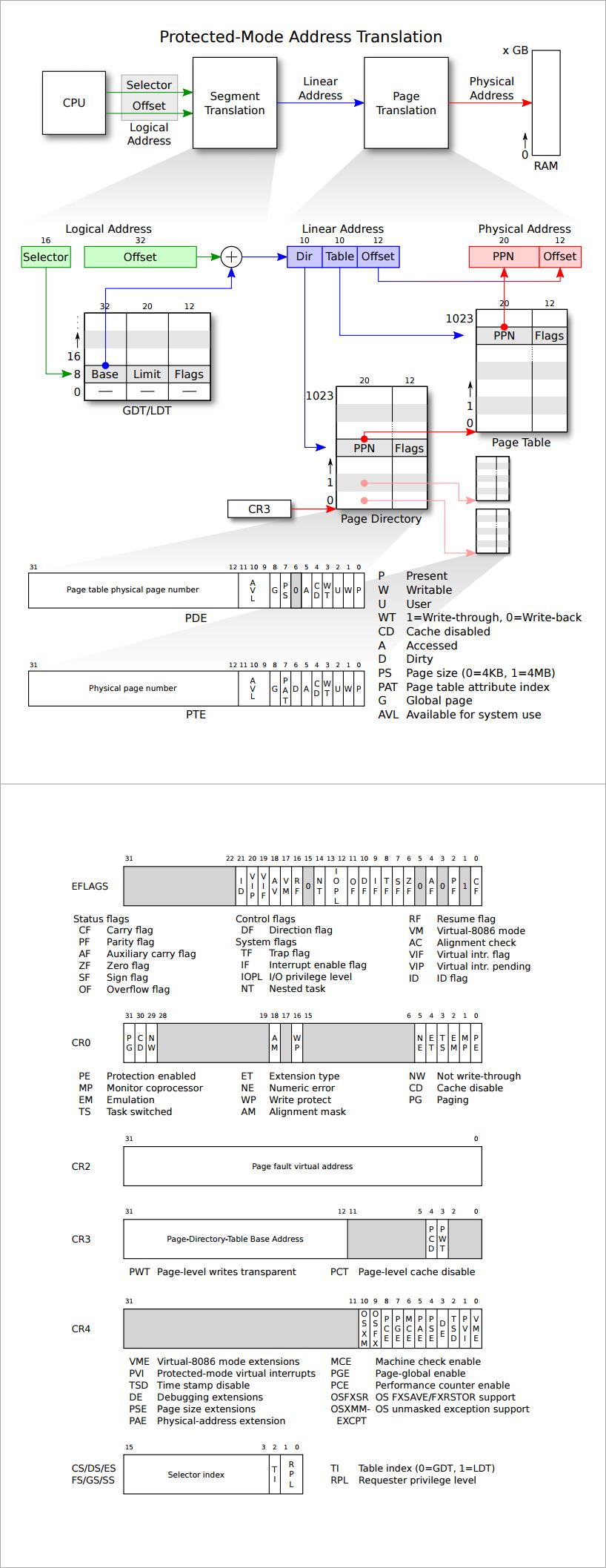
页表存储在哪里:
在 RAM 中——MMU 加载(和存储)PTE ;操作系统可以读写 PTE
是否可以认为页表是一个PTE数组?它有多大?
$2^{20}$是一百万 -> 每个条目32位 -> 整页表格为4MB
在早期机器上相当大,但会为小程序浪费大量内存!—— 你只需要几百页的映射,所以其余的百万条目将在那里但不需要。
x86使用“两级页表”来节省空间:
RAM中的PTE页面
RAM中的页面目录(PD)
PDE还包含20位PPN —— 1024个PTE组成的页面,1024个PDE指向PTE页面
每个PTE页面有1024个PTE——总共1024*1024个PTE
PD条目可能无效
那些PTE页面不需要存在,因此,小地址空间的页表可以很小
mmu如何知道页表在RAM中的位置?
%cr3保存PD的物理地址
PD保存PTE页面的物理地址
(它们可以在RAM中的任何位置 - 不需要连续)
x86寻页硬件如何翻译虚拟地址(va)?
- 定位正确的
PTE %cr3指向PD的PA- 高
10bit作为PD的索引来得到PT的PA - 之后的
10bit作为PT的索引得到PTE - 最终得到 【来自
PTE的PPN+VA的低12bit】
PTE 中的标志位:
P,W,U- xv6 使用
U来防止用户使用内核内存
如果没有设置P位怎么办? 或存储和W位未设置?
“页面错误”
CPU保存寄存器,强制转移到内核
trap.c在xv6源码中
内核能够产生错误,结束进程;或安装PTE,恢复进程
例如 从磁盘加载内存页面后
问:为什么映射而不是基址/约束?
- 间接允许分页
h/w解决许多问题,例如 - 避免碎片化
copy-on-write fork- 懒惰分配(下一课的家庭作业)
- 更多技术,下一讲的主题
问:为什么在内核中使用虚拟内存?为用户进程提供页表显然很好****但为什么需要内核的页表?
内核可以只使用物理地址运行吗?是的Singularity 是使用物理地址的示例内核但是,大多数标准内核都使用虚拟地址?为什么标准内核会这样做?
硬件使其难以关闭
例如在进入系统调用时,必须禁用VM
内核可以方便地使用用户地址,例如传递给系统调用的用户地址但是,可能是一个坏主意:内核/应用程序之间的隔离比较差
如果地址是连续的则很方便。例如内核有4Kbyte对象和64Kbyte对象,如果没有页表,我们很容易就会出现内存碎片
例如,分配64K,分配4Kbyte,释放64K,从64Kbyte分配4Kbyte现在一个新的64Kbyte对象不能使用空闲的60Kbyte。
内核必须运行各种硬件,而它们可能具有不同的物理内存布局
案例研究:xv6使用x86分页硬件
xv6中每个进程的地址空间
0x00000000:0x80000000 -- user addresses below KERNBASE
0x80000000:0x80100000 -- map low 1MB devices (for kernel)
0x80100000:? -- kernel instructions/data
? :0x8E000000 -- 224 MB of DRAM mapped here
0xFE000000:0x00000000 -- more memory-mapped devices
xv6内存映射的对饮关系——课本,或者代码注释 (mem_layout.h)
每个进程都有独立的地址空间和页表,但所有的进程有相同的内核映射(高内存地址片段)
内核通过切换页表,(例如设置 %cr3)来切换进程
问:为什么这样安排地址空间?
用户虚拟地址从零开始,那么用户的虚拟地址 va: 0 对于每个进程映射不同的 PA
虚拟内存中2GB大小的用户堆连续增长,但不需要连续的物理内存 —— 内核和用户映射都不会产生碎片问题—— 易于系统调用的切换,中断在所有进程的相同位置映射内核
简化进程切换
内核能方便地读写用户内存
pa x 映射到 va x + 0x80000000 ,我们很快就会在操作页面表时看到这一点
这样的视图下能承载的最大进程?
是否能增加这样的最大进程,通过增加或减少 0x80000000?
内核是否必须将所有的物理内存映射到其虚拟地址空间?
let's look at some xv6 virtual memory codeterminology: virtual memory == address space / translationwill help you w. next homework and labs
-
where did this pgdir get setup?look at vm.c: setupkvm and inituvm
-
mappages() in vm.carguments are PD, va, size, pa, permadds mappings from a range of va's to corresponding pa'srounds b/c some uses pass in non-page-aligned addressesfor each page-aligned address in the rangecall walkpgdir to find address of PTEneed the PTE's address (not just content) b/c we want to modifyput the desired pa into the PTEmark PTE as valid w/ PTE_P
-
diagram of PD &c, as following steps build it
-
walkpgdir() in vm.cmimics how the paging h/w finds the PTE for an addressrefer to the handoutPDX extracts top ten bits&pgdir[PDX(va)] is the address of the relevant PDEnow *pde is the PDEif PTE_Pthe relevant page-table page already existsPTE_ADDR extracts the PPN from the PDEp2v() adds 0x80000000, since PTE holds physical addressif not PTE_Palloc a page-table pagefill in PDE with PPN -- thus v2pnow the PTE we want is in the page-table pageat offset PTX(va)which is 2nd 10 bits of va
-
tracing and date system call
-
a process calls sbrk(n) to ask for n more bytes of heap memorymalloc() uses sbrk()each process has a sizekernel adds new memory at process's end, increases sizesbrk() allocates physical memory (RAM)maps it into the process's page tablereturns the starting address of the new memory
-
sys_sbrk() in sysproc.c
-
growproc() in proc.cproc->sz is the process's current sizeallocuvm() does most of the workswitchuvm sets %cr3 with new page tablealso flushes some MMU caches so it will see new PTEs
-
allocuvm() in vm.cwhy if(newsz >= KERNBASE) ?why PGROUNDUP?arguments to mappages()...