Performance Issues
Longest delay determines clock period
- Critical path: load instruction
- Instruction memory → register file → ALU → data memory → register file
Not feasible to vary period for different instructions
Violates design principle
- Making the common case fast
We will improve performance by pipelining
MIPS Pipeline
Pipeline: an implementation technique in which multiple instructions are overlapped in execution
Five stages, one step per stage
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Execute operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
Performance: 耗时最长的stage决定时钟周期
Speedup:
- If all stages are balanced (all take the same time)
- $Time,between,instructions_{pipelined} = \frac{Time,between,instructions_{nonpipelined}}{Number,of,stages}$
- else
- 除以耗时最长的stage
Speedup due to increased throughput, Latency does not decrease.
Pipelining and ISA Design
与以x86为代表的CISC指令集比较
- MIPS ISA designed for pipelining
- All instructions are 32-bits
- Easier to fetch and decode in one cycle
- Few and regular instruction formats
- Can decode and read registers in one step
- Load/store addressing
- Can calculate address in 3rd stage, access memory in 4th stage
- Alignment of memory operands
- Memory access takes only one cycle
Hazards
Situations that prevent starting the next instruction in the next cycle
Structure hazards
- A required resource is busy
- RAM数据的读写与ROM指令数据的读取
- Improved by Separating instruction/data caches
Data hazard
- Need to wait for previous instruction to complete its data read/write
- 如赋值后紧接着读取
- Improved by Forwarding & Code Scheduling
Control hazard
- Decisions of control action depends on the previous instruction
- 跳转信号结果的计算
- Improved by Predicting
Structure Hazards
- Conflict for use of a resource
- If MIPS pipeline has only one memory (data and instructions all in one), then
- Load/store requires data access
- Instruction fetch would have to stall for that cycle
- Hence, pipelined datapaths require separate instruction/data memories
- Or separate instruction/data caches
Data Hazards
An instruction depends on completion of data access by a previous instruction
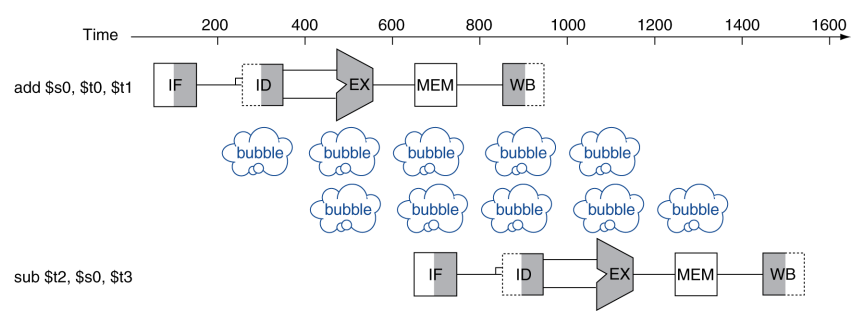
add $s0, $t0, $t1
sub $t2, $s0, $t3
$s0 的写入后立即读取产生 data hazard,产生两个 bubble
Control Hazards
Branch determines flow of control
Fetching next instruction depends on branch outcome
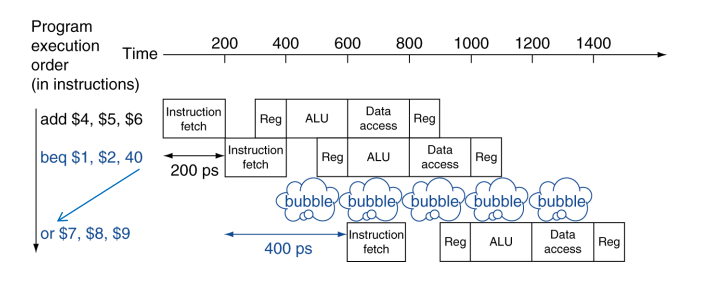
Pipeline can’t always fetch correct instruction
- Still working on ID stage of branch
In MIPS pipeline
- Need to compare registers and compute target early in the pipeline
- Add hardware to do it in ID stage
Improvement of hazard
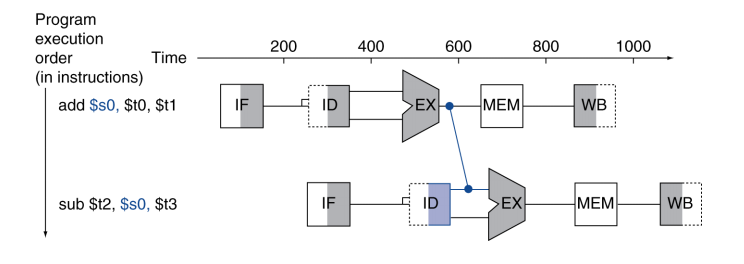
Forwarding (aka Bypassing)【Improve Data Hazard】
Forwarding can help to solve data hazard
Core idea: Use result immediately when it is computed
- Don’t wait for it to be stored in a register
- Requires extra connections in the data path
- Add a bypassing line to connect the output of EX to the input
通过额外的连线来传输数据
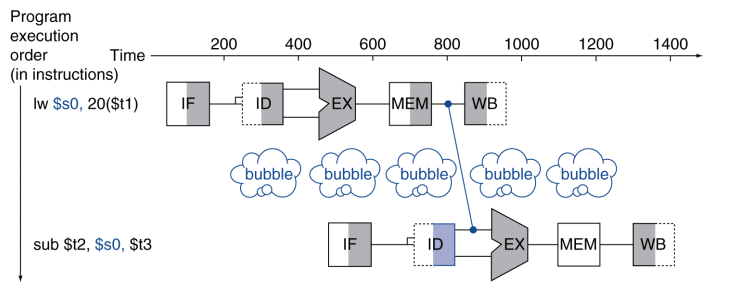
Can’t always avoid stalls by forwarding
- If value not computed when needed
- Can’t forward backward in time
不能完全避免因为内存读取产生的stall,(结果不能再EX stage后获取,只能减少一个bubble)
Code Scheduling to Avoid Stalls【Improve Data Hazard】
- Reorder code to avoid use of load result in the next instruction (avoid “load + exe” pattern)
尽量避免数据从内存载入后的立即使用

Branch Prediction
通过概率避免 stall,不能完全解决
- Longer pipelines can’t readily determine branch outcome early
- Stall penalty becomes unacceptable
- Predict outcome of branch
- Stall only if prediction is wrong
- In MIPS pipeline
- Can predict branches not taken
- Fetch instruction after branch, with no delay
More-Realistic Branch Prediction
Static branch prediction
编译器根据语法进行预测
- Based on typical branch behavior
- Example: loop and if-statement branches
- Predict backward branches taken
- Predict forward branches not taken
Dynamic branch prediction
基于硬件的预测:统计历史;假设与历史相同
- Hardware measures actual branch behavior
- record recent history of each branch
- Assume future behavior will continue the trend
- When wrong, stall while re-fetching, and update history
Summary
- Pipelining improves performance by increasing instruction throughput
- Executes multiple instructions in parallel
- Each instruction has the same latency
- Subject to hazards
- Structure, data, control
- Instruction set design affects complexity of pipeline implementation