使用图表清晰的展示了管道的工作方式
i> 注意:理解这篇文章需要基本熟悉Unix命令和C / C ++。 我的目标是在运行命令时解释进程之间的数据流。 如果您想直接跳转到管道内容,请单击此处。
在这篇文章中,我们将讨论Unix命令如何通过管道和输入/输出重定向将数据相互传递,并且我将说明执行命令时数据流实际发生的情况。
文件描述符 - File Descriptors
从基本的 “在键盘上键入内容,按回车键,并获得结果” 模型开始,在终端中运行单个命令而不进行输入/输出重定向。 在本文的讨论中,我们将输入和输出称为进出流程(into and out)的文本数据。
Unix将输入与终端键盘关联,并默认输出终端显示。 Unix以将计算机中的所有内容建模为文件(包括键盘和显示器)而闻名。 因此,写入“显示”实际上只是写入管理屏幕上数据显示的文件。 类似地,从键盘读取数据意味着从代表键盘的文件中读取数据。
数据通过流将字节从一个区域传输到另一个区域。有三个默认输入/输出(I / O)流:
- 标准输入(
stdin = 0) - 标准输出(
stdout = 1) - 标准错误(
stderr = 2)
默认情况下,这些流都具有特定的文件描述符。文件描述符是与打开文件相关联的整数(其工作范围超出了本讨论的范围),并且进程使用文件描述符来处理数据。三个默认流具有以下文件描述符编号:stdin = 0,stdout = 1和stderr = 2.文件描述符存储在文件描述符表中,每个进程都有自己的文件描述符表(0,1和2创建进程时默认创建并映射到其相应的流)。
每个数据流只了解描述符本身,而对其背后的文件不清楚,即数据流只处理文件描述符而非数据源;
因此进程只需要处理文件描述符,文件本身由内核安全地管理。
数据流 - Data Flow
现在我们准备好深入讨论数据流。 当我们在终端中运行命令时,需要适当地处理任何输入和输出。 每个命令都需要知道输入哪些数据(如果有的话)以及可能输出的数据。 每个命令还需要知道发送和接收此类数据的位置。 为了表示数据流(默认情况下通过键盘输入stdin)和输出(默认情况下通过stdout输出到终端,如果出现问题,还可以通过stderr),我将使用如下图所示的图表:

标准输入(0)和输出(1)流的概念数据流
上图表示了输入输入流地默认步骤。使用键盘将输入数据传递给程序指令(从指令角度来看,通过 stdin 来接受输入),之后程序通过 stdout 将输出数据发送给终端。我还使用in和out来表示分别进入一个区域和另一个区域的数据。虽然在这种情况下in和out分别与stdin和stdout相关联,但在将来的图中不一定是这种情况。因此,我将文件描述符号放在与相关in/out操作相对应的相关“文件”旁边,以便清楚哪个文件描述符用于哪个目的。通常,“流入”某物的数据被视为输入(并且正通过文件描述符从源读入),并且“流出”某物的数据被视为输出(并且通过文件描述符被写入源) 。换句话说:输入是从某处读取;输出是写在某处。这种心理模型将在未来更复杂的图表中证明是有用的。
需要注意的一点是,实际上有两个流可以默认将输出写入终端:stdout 和 stderr 。 当尝试执行命令时出现错误时,将使用 stderr 流。 例如,下面是在我的终端中使用 ls dir_x 命令尝试列出不存在的目录 dir_x 的内容:
|
|
在这个例子中,用于显示第二行的流实际上是 stderr,而不是 stdout。 由于 stderr 默认也会转到终端,因此我们会在终端中看到错误消息。 如果目录存在,那么 stdout会将目录的内容输出到屏幕。
这是一个更新的图表,展示了 stdout 和 stderr 的流的输出端:

标准输入(0),输出(1)和错误(2)流的概念数据流
请记住,“out”一词仅表示输出,且与其相关的文件描述符在其旁边显示。 既然您已经了解了stderr的存在并且可以使用,我实际上将其从未来的数据流图中删除,除非示例专门使用stderr。 请记住它存在!
现在我们可以使用命令行探索数据流。一些命令既读取输入又写入输出,其他命令只执行一个或两个都不执行。我们将探讨不同的情况,但首先,让我们讨论一下输入在这里的意义。从技术上讲,从shell的角度来看(shell处理给终端的命令行),键入键盘的任何东西(包括命令本身)都是一般意义上的“输入”,但我们专门处理输入和命令所需的输出,以便运行命令的进程与文件(包括键盘和显示器)之间传输数据。作为选项的命令参数实际上是从命令行读入的(作为参数数组);从与文件描述符相关联的打开文件中读入实际输入。因此,我将命令的输入定义为使用 stdin(或可以读取的另一个重新调整的文件描述符)专门传入的数据,无论是通过键盘输入,还是通过I / O重定向重定向(稍后解释),或者可能作为文件参数传递给命令(与选项参数相对)。如果一个文件作为参数传递并且进程将实际读取或操作该文件的内容(例如,对内容进行排序),而不是简单地引用文件本身(例如,移动或重命名它),那么我认为它是输入 。
另外,命令行选项参数是另一个Unix设计选择的结果,它允许将执行的命令的行为修改与接收的输入分开传递。 保持参数和输入分开可以在涉及管道时更轻松。
现在让我们看一些例子。 一个没有输入但有输出的命令,可以考虑 ls——列出当前目录中的所有文件:
|
|
这可以用下图形象地展示:
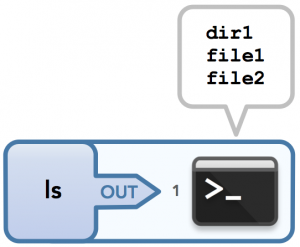
ls 命令
如果命令不接受来自stdin的输入,那么传递给这样一个命令的数据将被运行该命令的程序忽略,因为它没有被写入来处理输入数据。 例如,<words.txt ls将列出当前目录中的文件和目录,并忽略重定向到stdin的输入(这使用I / O重定向,稍后我会解释)。
我们来看看下一个不接受输入并且不输出地命令——mv,它可以用来移动或重命名文件。 如果我给它一个可以成功移动或重命名的文件或目录的名称,那么就不会通过stdout或stderr输出数据。 请记住,由于此文件的内容未以任何方式被读取或使用,因此传入的文件不被视为输入。 在成功调用此命令后,我将拥有这个非常简单的图表:

没有输入和输出
但是,如果我错误地使用mv以便发生错误,那么我将输出到stderr:
|
|
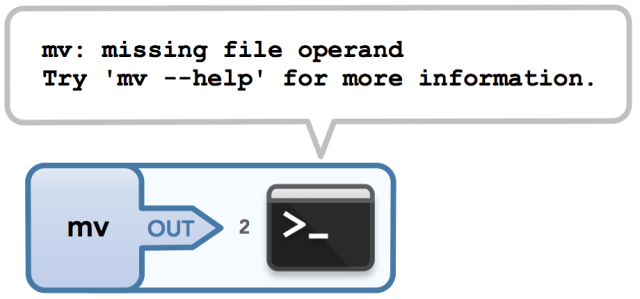
没有参数地调用 mv
让我们把事情变得更有趣。 我最喜欢的一个读取输入和写入输出的命令示例是sort。 当没有文件参数且没有输入重定向时,终端等待用户输入要排序的字符串(每行一个字符串)。 一旦用户键入Ctrl-D(这将关闭连接键盘到sort进程的stdin的通信通道的写端),运行sort的进程将知道已输入所有所需的字符串。 因此,这些字符串通过stdin传递到运行命令的进程中,按所述进程排序,然后通过stdout写入终端。 太漂亮了! 这是输入/输出示例:
|
|
粗体字符串是用户输入,后面的字符串表示排序的输出。 以下是此示例的数据流:
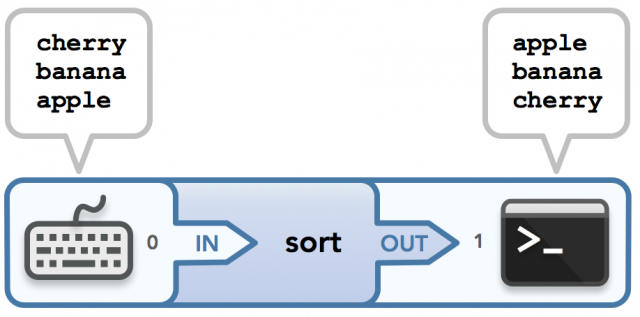
sort命令。从键盘输入,然后输出按排序顺序显示
请注意,sort也可以使用filename参数从指定文件获取输入,而不是等待用户输入数据(例如,sort words.txt),这是我们输入的定义,因为它是一个文件而不是 sort -r中的选项参数。 另外,sort可以通过输入重定向获取输入,我将在后面解释。
现在我们了解了从stdin到stdout或stderr的数据流的一般概念,我们可以讨论如何控制输入和输出的流程。 我将介绍两种方法:
- 使用管道,允许一个进程的输出作为输入传递到另一个进程
- 使用I / O重定向,允许文件作为数据的源和目标而不是 默认键盘和终端。
管道 - Pipe
Unix有一个简单但有价值的设计理念,正如Unix管道的发明者Doug McIlroy所解释的那样:
“Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.”
管道的概念非常强大。 管道允许将来自一个进程的数据传递给另一个进程(通过单向数据流),以便命令可以通过数据流链接在一起。 这允许不同命令一起工作以实现更大的目标。 流程的链接可以由管道表示:管道中的命令通过管道连接,其中数据通过从管道的一端流到另一端而在流程之间共享。 由于管道中的每个命令都在一个单独的进程中运行,每个进程都有一个单独的内存空间,因此我们需要一种方法来允许这些进程相互通信。 这正是pipe()系统调用提供的行为。
在实现方面,管道实际上只是与设置的两个文件描述符相关联的缓冲流,以便第一个可以读入数据并写入第二个文件的。 具体来说,在为处理管道中的命令执行而编写的代码中,创建了两个整数的数组,并且pipe()调用使用两个可用文件描述符(通常是最低的两个可用值)填充数组,以便第一个文件 数组中的描述符可以读入写入第二个的数据。
物理管道自然是这种抽象的一个很好的类比。 我们可以将在一个过程中开始的数据流视为隔离环境中的水,并且允许水流入下一个过程的环境的唯一方法是使用管道连接环境。 通过这种方式,水(数据)从第一环境(过程)流入管道,用所有水填充管道,然后将水排放到另一个环境中。 这个数据流正是我试图在图中捕获的以下管道示例,sort | grep ea:
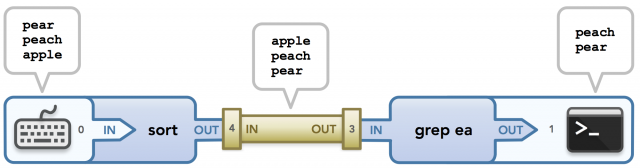
sort | grep ea
让我们逐个击破。 和先前的示例一样,sort命令通过stdin(文件描述符0)等待来自用户(输入三个字符串以进行排序)的输入。 接下来,字符串被排序并通过stdout作为输出发送,stdout被送入管道。 这是因为Unix允许stdout将数据提供给管道的左端(文件描述符4)而不是终端来实现。 我在这里省略了一个细节,但这个过程将在本文后面进行更深入的解释。
在继续之前,这里有一个重要的细节:还记得我提到每个进程都有自己的文件描述符表吗? 好吧,因为管道中的每个命令都在一个单独的进程中运行,所以每个命令都有自己的文件描述符版本,包括它自己的stdin,stdout和stderr。 这意味着图的0和1在不同的文件描述符表中,其中0属于运行sort的进程,1属于运行grep的进程。 但是,由于流被设置为发送超出进程边界的数据,因此只要它正确传递到管道,最终结果就是位置结束的数据。
接下来:既然sort命令有一个排序的字符串列表作为输出,它必须将它传递给创建的管道,以便将数据传递给下一个进程grep。 暂时忽略文件描述符3和4,查看“in”和“out”字样:我们看到数据流出sort进程并进入管道,然后它从管道传递到grep中 处理。 “In”和“out”基于它们所使用的上下文来表达:在管道内部或在管道外部。
考虑到这一点,我们现在可以讨论pipe()调用分发的文件描述符。 假设在执行管道中的命令的代码中,pipe()调用填充文件描述符数组{3,4},以便可以从3读取写入4的数据。(这些数字是什么并不重要 甚至他们只是升序)想象一下一个数组{pickle,mickeymouse}; 给定的值只对进程有影响,但每个文件描述符的目的对数据很重要! 每个文件描述符的目的取决于每个数组中的索引。
这里有一个非常重要的概念,一个让我花了一段时间才能最终理解的概念(直到我创建这些图表时才发生这种情况,因为我的视觉大脑的工作方式)。回想一下,在我的思考模型中,数据在图中从左向右流动。文件描述符被设置数组中以便可以从3读取写入4的内容,因此您可能想知道为什么在上图中管道左侧显示4、右侧显示3。需要理解的关键是,pipe()调用定义的读写操作是从使用管道的两个进程的角度来看,而不是管道本身!因此,当pipe()调用将4定义为管道的可写端时,这意味着它是第一个命令的进程的输出末端,以便管道本身接收该数据作为输入。(但反过来不是这样:4是管道中管道的输出端,这会诱使您将管道的右侧标记为4)同样,3是管道的可读端意味着它是第二个命令进程从中读取数据的管道的末尾。这完全取决于角度! :)
就这样,数据被传递到管道,一直放到所有的数据被传递到到grep进程【实际上管道是类似队列的FIFO原则】。 作为最后也是相对简单的步骤,运行grep的进程搜索从管道输出端接收的包含"ea”的行的输入。 然后,它使用其stdout流将匹配的字符串输出到终端。 全部完成! 对我们的第一次管道演练来说不错! 接下来,我们将深入了解代码如何执行这些过程。 在我看来,我们对pipe()如何工作的理解是成功的一半。 理解fork()和dup2()是另一半。 让我们看看这些功能是如何工作的!
在管道中运行命令 - Running Commands in a Pipeline
在我们到目前为止看到的图中,在将数据从一个命令的进程传递到另一个命令的过程中使用了管道,但是我们还没有讨论运行这些命令的进程的层次结构。 在课堂上,我们学习了编写程序,使得每个命令都在子进程中执行,而不是父进程(调用进程)中执行。 通常,父进程执行所有必要的设置,然后通过fork()调用创建子进程,在这个过程克隆父进程的内存状态及文件描述符。 因此,子项最终会得到fork()调用时父项中存在的变量和文件描述符的独立副本。 在fork()调用之后,父进程的更改将对子进程不可见,反之亦然。
这个children-execute-commands模块对于执行单个命令似乎是不必要的,因为我们可以简单地在父节点中运行命令而不创建子节点,但是当您考虑使代码通用到足以同时用于单个命令或管道中的多个命令,那么就有理由让不同的子进程执行每个命令。 此规则有例外,例如运行可以在父级中运行的内置命令,但是对于本讨论,我们假设所有命令都在子进程中执行。
让我们看一下运行sort命令的一些C代码的迂腐示例。 在此示例中,使用dprintf()将输入直接打印到文件描述符,以显示使用管道将数据从父级发送到子级的情况。 这是我们的讲师Jerry向课堂提供的示例代码的简化版本:
|
|
编写该程序以运行一个特定的命令:sort。以下是代码的工作原理:在父进程中,创建一个数组来存储两个文件描述符。在pipe()调用之后,使用挂钩的文件描述符填充数组,其中第一个将被子进程读取,第二个将由父进程写入。然后调用fork()来创建子进程,该进程具有父进程的文件描述符和内存的副本。之后,检查程序是否在子进程中运行。如果是,则子进程调用dup2()使其stdin与管道的可读端相关联,这对应于fds[0]。关于dup2()工作方式的一个重要细节是,如果需要,它将首先关闭其第二个参数,即文件描述符。因此,在此示例中,首先关闭stdin(默认情况下是打开的),这将删除其对默认键盘文件的引用。然后子进程的stdin将能够通过fds [0]而不是键盘接收数据。这就是dup2()的魔力!
现在子进程的stdin已准备好读入数据,它关闭了pipe()调用创建的文件描述符,因为子进程不再需要它们。 然后,子进程执行sort命令,等待所有父数据在排序数据之前写入管道末端。
调用fork()时,子进程可能会在父进程继续之前运行,在这种情况下,子进程将挂起,直到收到所有输入。 一旦sort命令结束运行,子进程在execvp()调用(执行给定命令)之后结束并自动关闭其默认文件描述符0,1和2。在创建子节点的fork()调用之后,父进程关闭fds[0],因为父进程不需要它(父进程只需要写入数据,而不是读取它)。然后,父进程将给定数组中的每个单词写入管道的可写端(fds[1]),在末尾添加一个新行字符,以允许sort命令正确接收新行上的每个单词。当所有单词都被写入后,父进程将关闭fds[1],因为它已完成写入数据,该数据向子进程发送EOF以允许它执行sort命令。在退出之前,父进程会等待子进程运行结束(通过waitpid()调用)。最后一行只是一种整齐的方式来返回一个值,该值取决于事情是否按预期进行。
完成所有操作后,这是整个事件序列的数据流图:
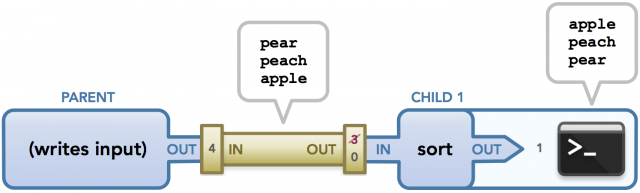
代码示例的最终数据流。在子进程中,文件描述符3被复制到子进程的stdin,然后3被关闭,只有子进程的stdin用于获取数据,如管道右侧的数字所示。
!> 这里应该是关闭0,dup2(old_fd, new_fd) 是用新的替换旧的
需要注意这个示例显示了如何使用管道,但在这种情况下不需要管道。 例如,孩子可以简单地从默认的stdin访问数据而不受父母的任何干扰,这不需要使用管道。 此代码仅显示管道如何设置从一个进程到另一个进程的通信,并且在管理具有多个命令的管道时,此模式至关重要。
为了了解此代码中发生的情况,我设计了以下图表。 在下面的图像中,这些行显示了文件描述符与它有指针的打开文件之间的关联。 线箭头方向表示数据流。 这些图表应该有助于明确父和子需要哪些文件描述符,这反过来应该有助于解释何时关闭文件描述符以避免泄漏。 另请注意,由于父母中的说明不能保证在孩子的指示之前运行,因此下面的一些步骤可能会在不同的时间发生。 这些图片只是为了让您了解执行过程中可能发生的事情,即使可以在此过程中交换几个步骤。
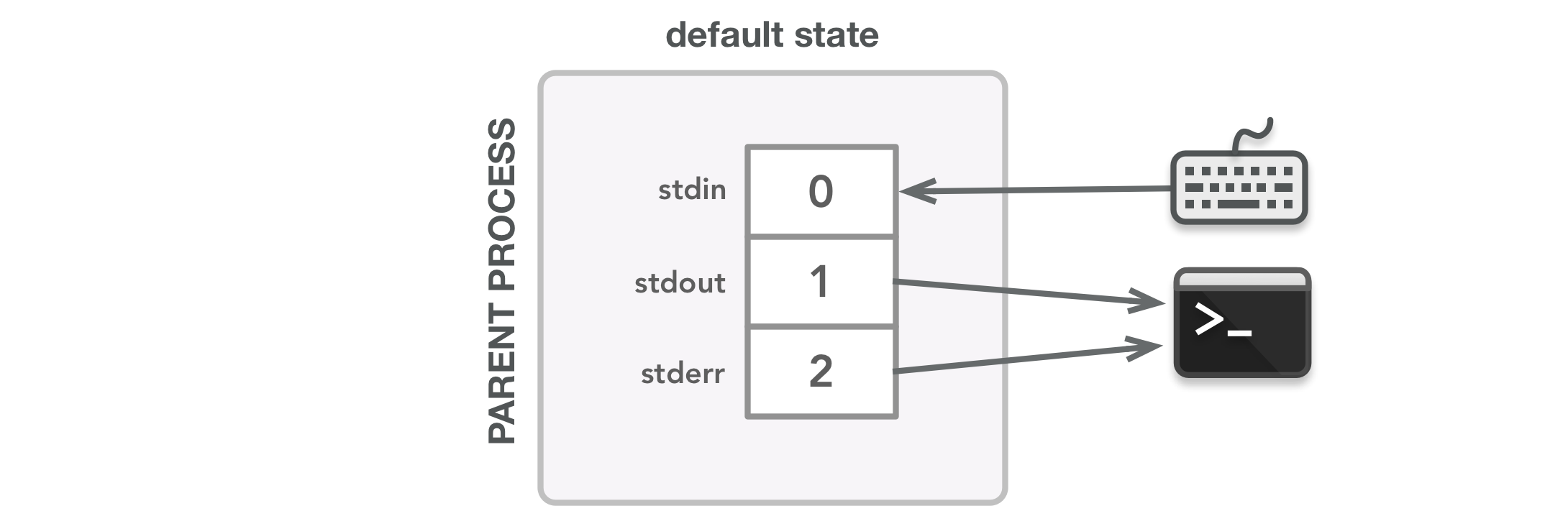
程序启动时,使用在其文件描述符表中设置的默认流创建父进程。箭头显示数据流:stdin接收来自键盘的输入,stdout和stderr将输出发送到终端显示器。
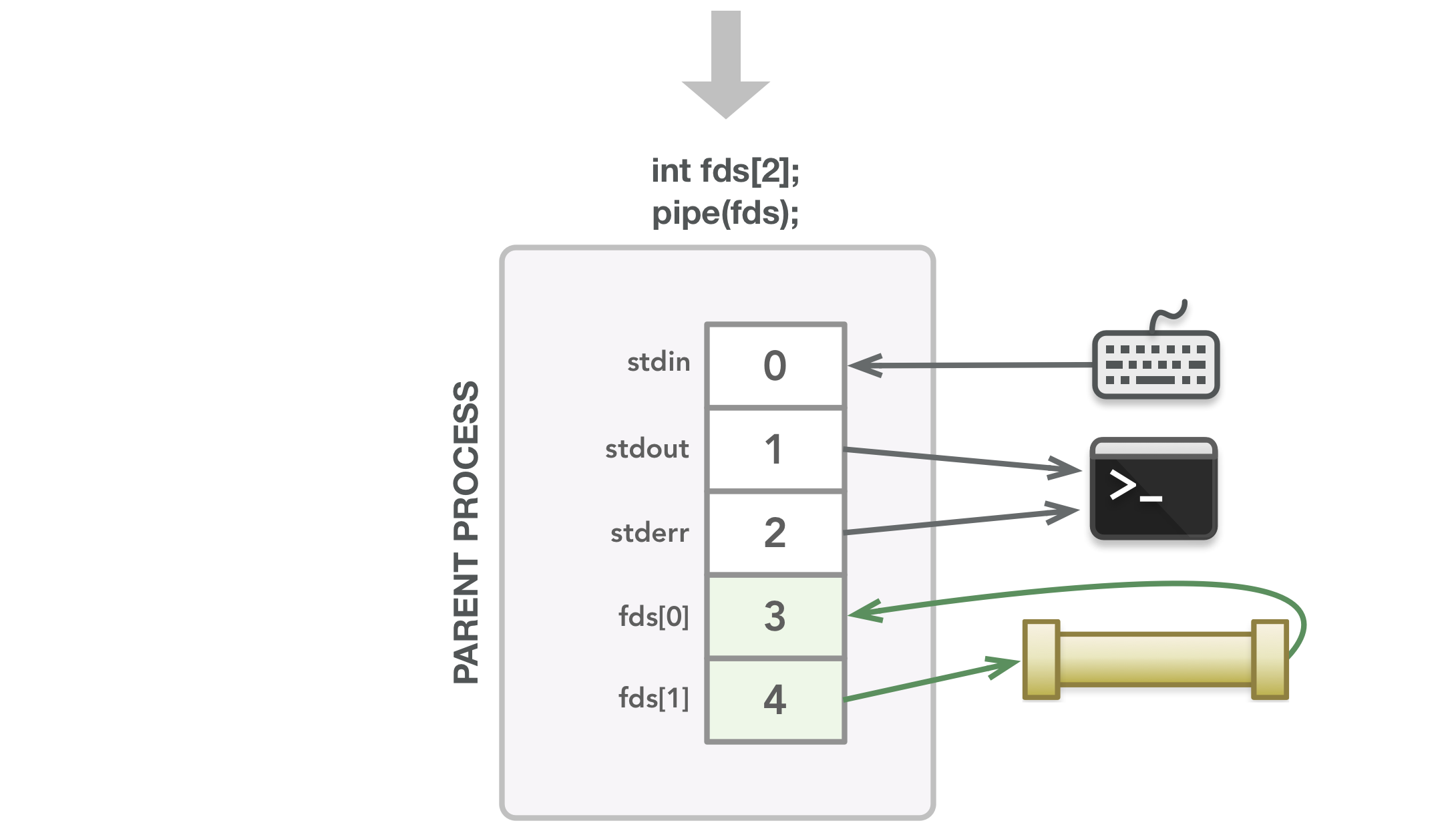
pipe()调用查找接下来的两个可用文件描述符,并将每个描述符与创建的管道的相应末尾相关联。在这种情况下,进程可以通过3读取并通过4写入。
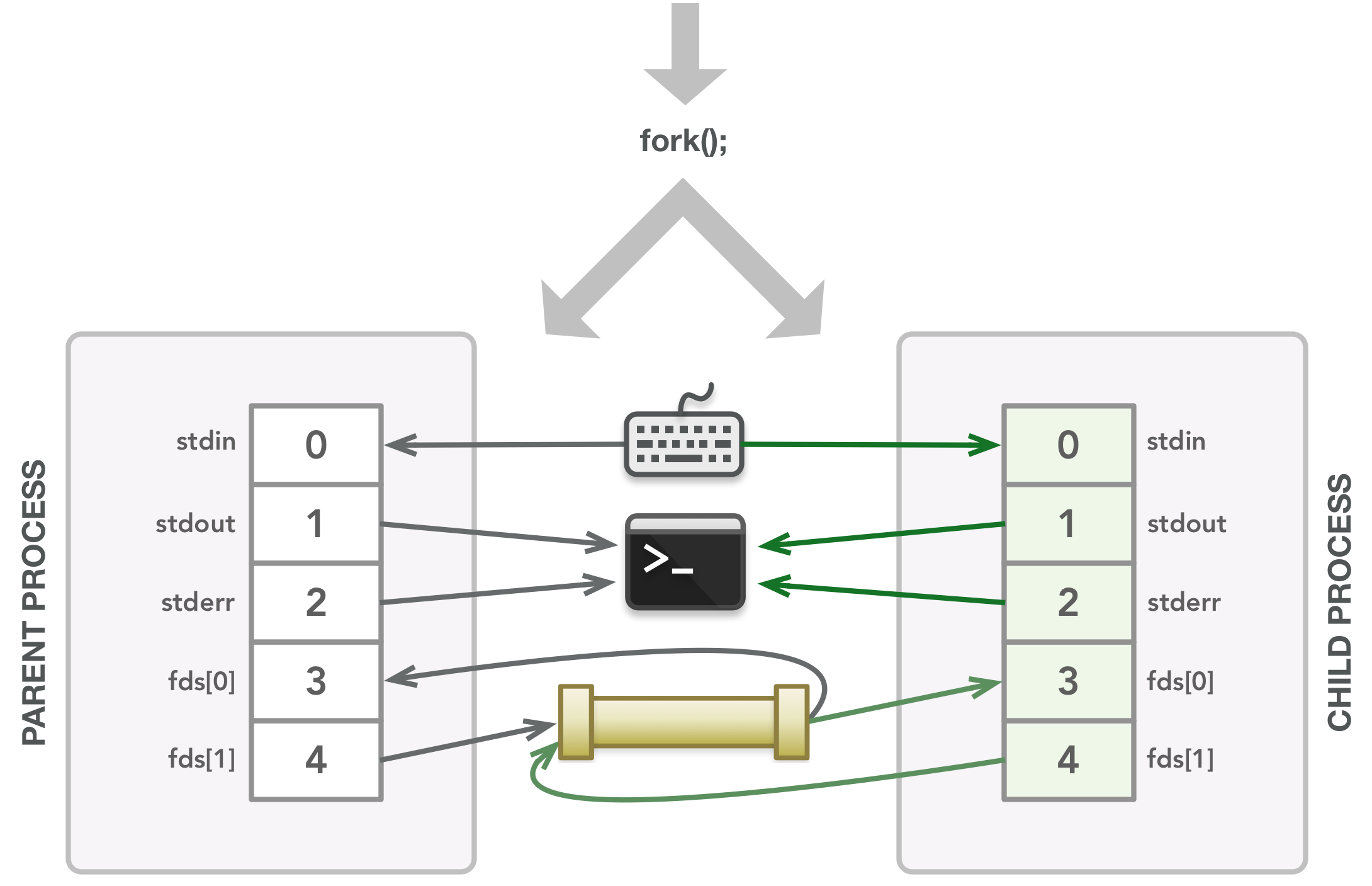
fork()调用创建子进程,该进程是该时间点父进程的内存和文件描述符表的副本。父文件描述符与之关联的文件与子文件描述符关联的文件相同。
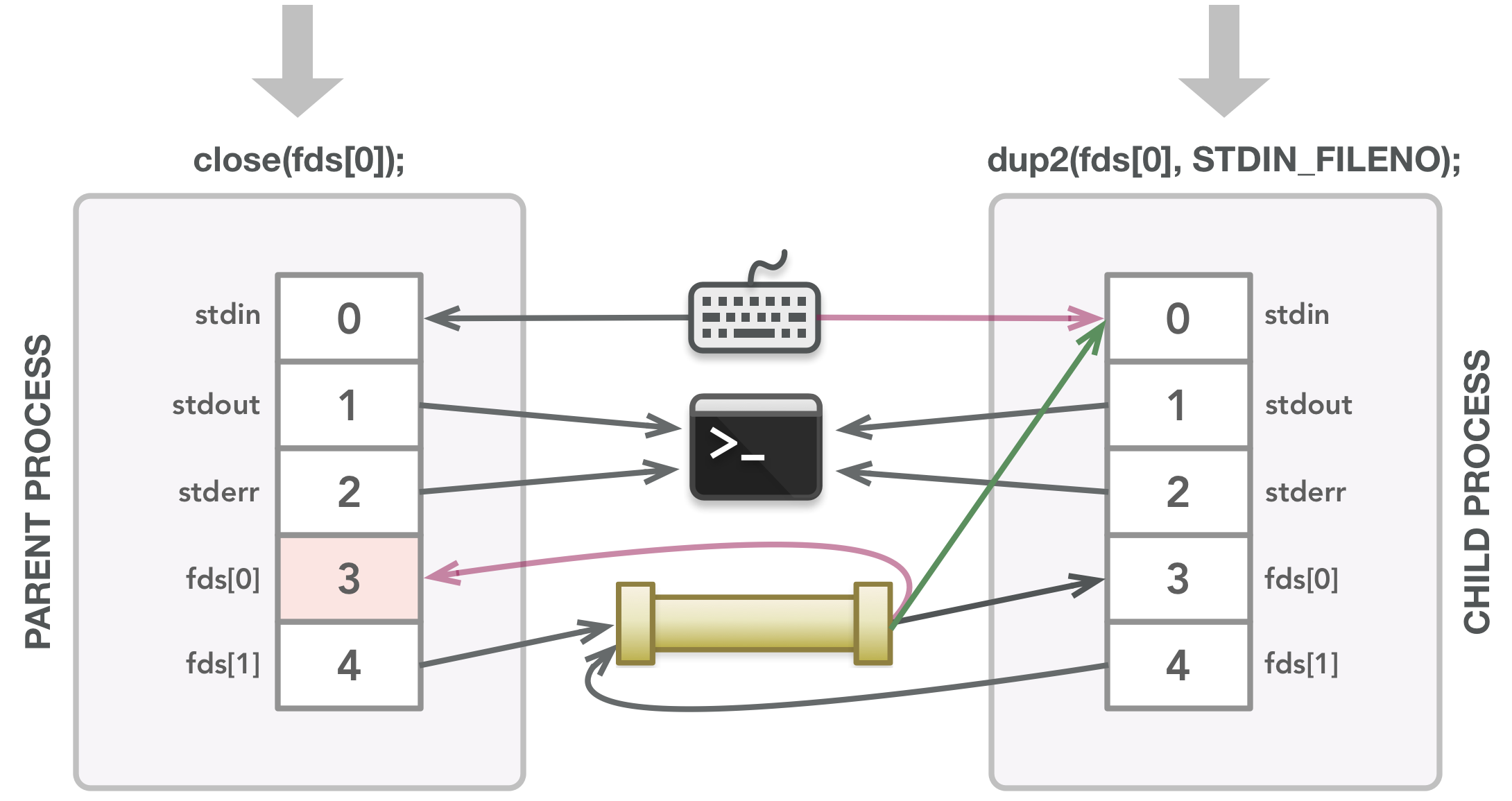
父关闭它不需要的文件描述符。子调用dup2()使其stdin成为fds[0]的副本,首先关闭文件描述符0。
图中漏关了父进程的 fd[]0
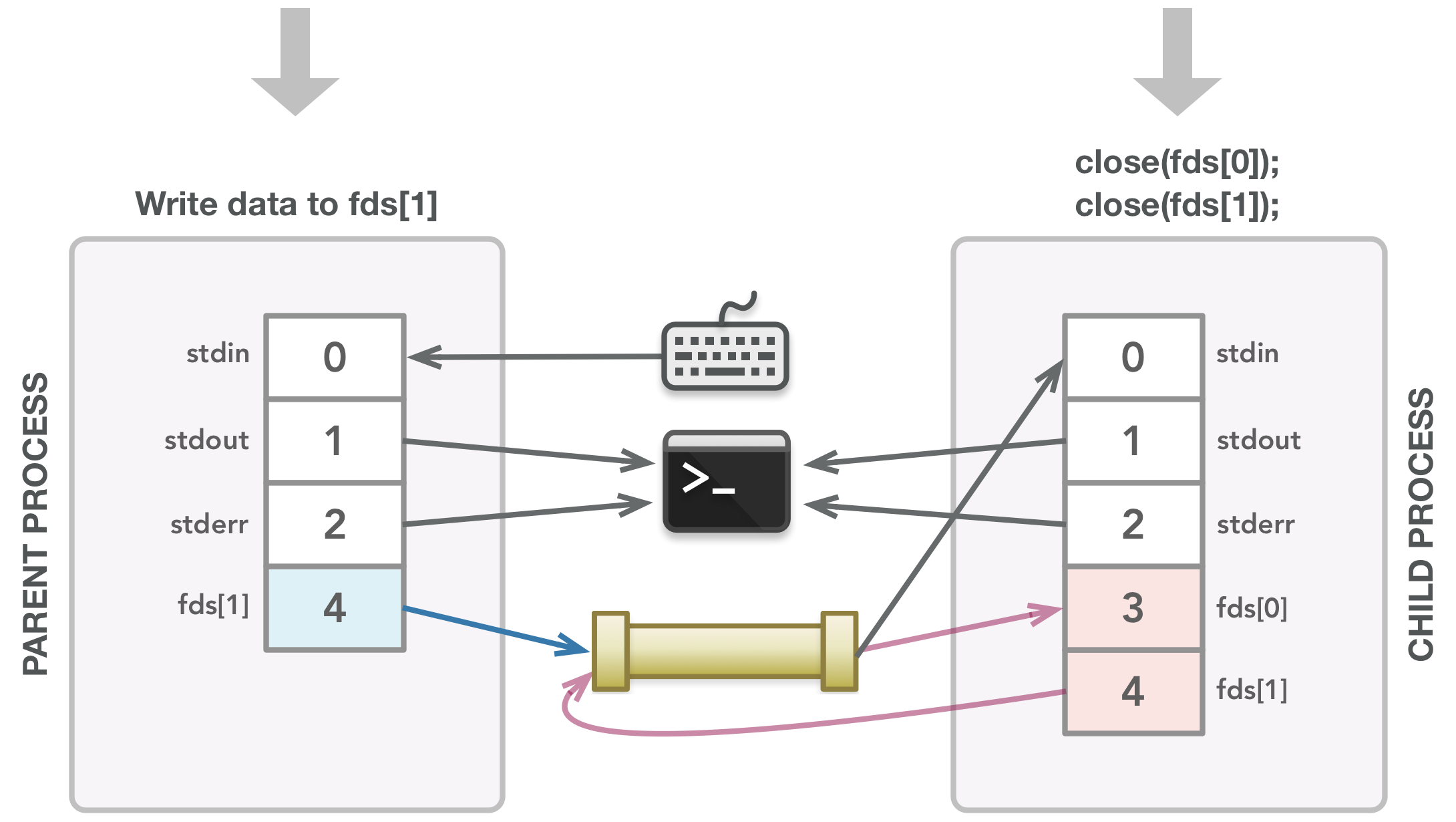
父进程将数据写入管道的可写端。子进程关闭它不需要的文件描述符。
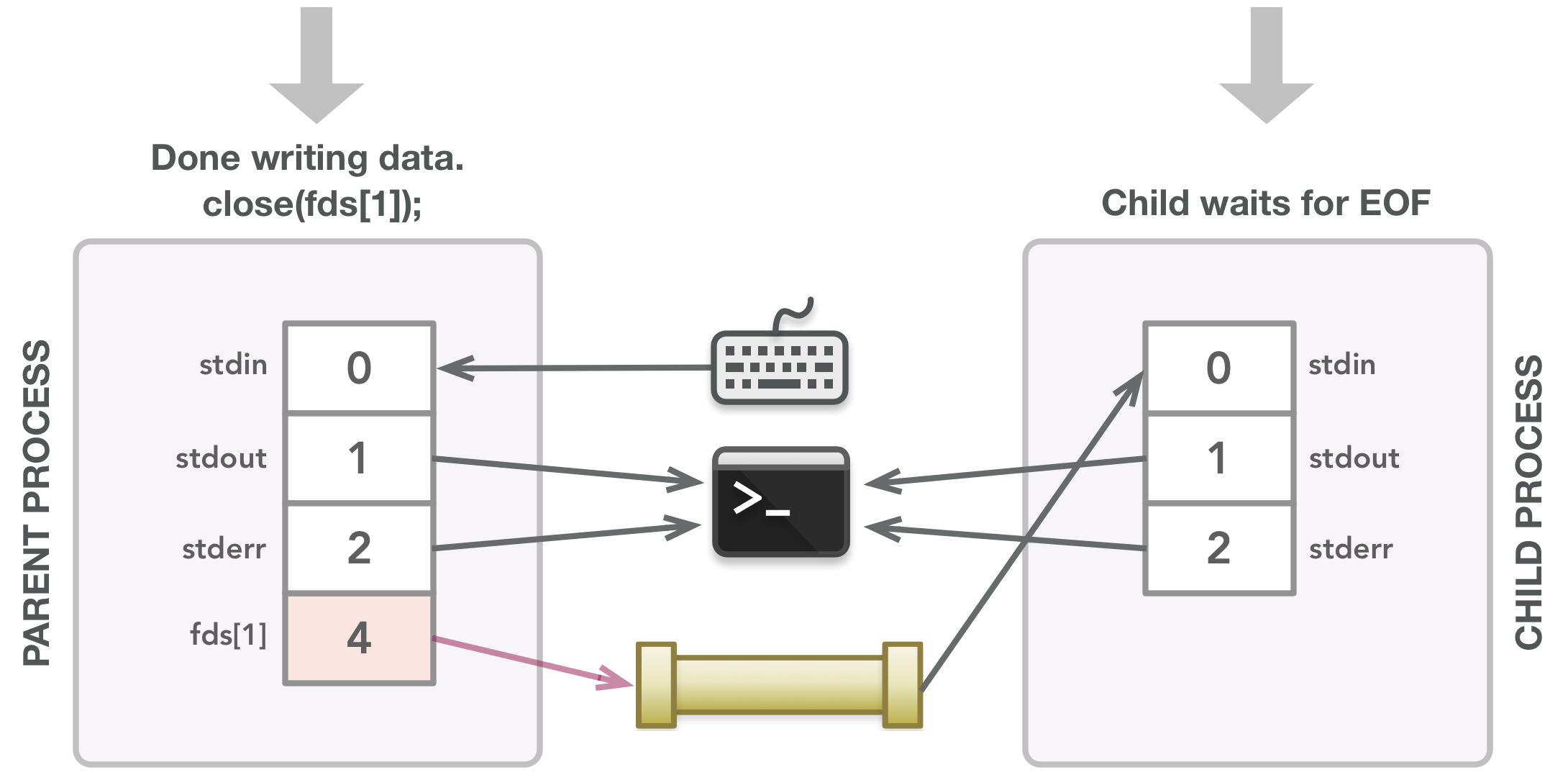
在写完所有数据后,父进程关闭fds[1]让子进程知道所有数据都已发送。
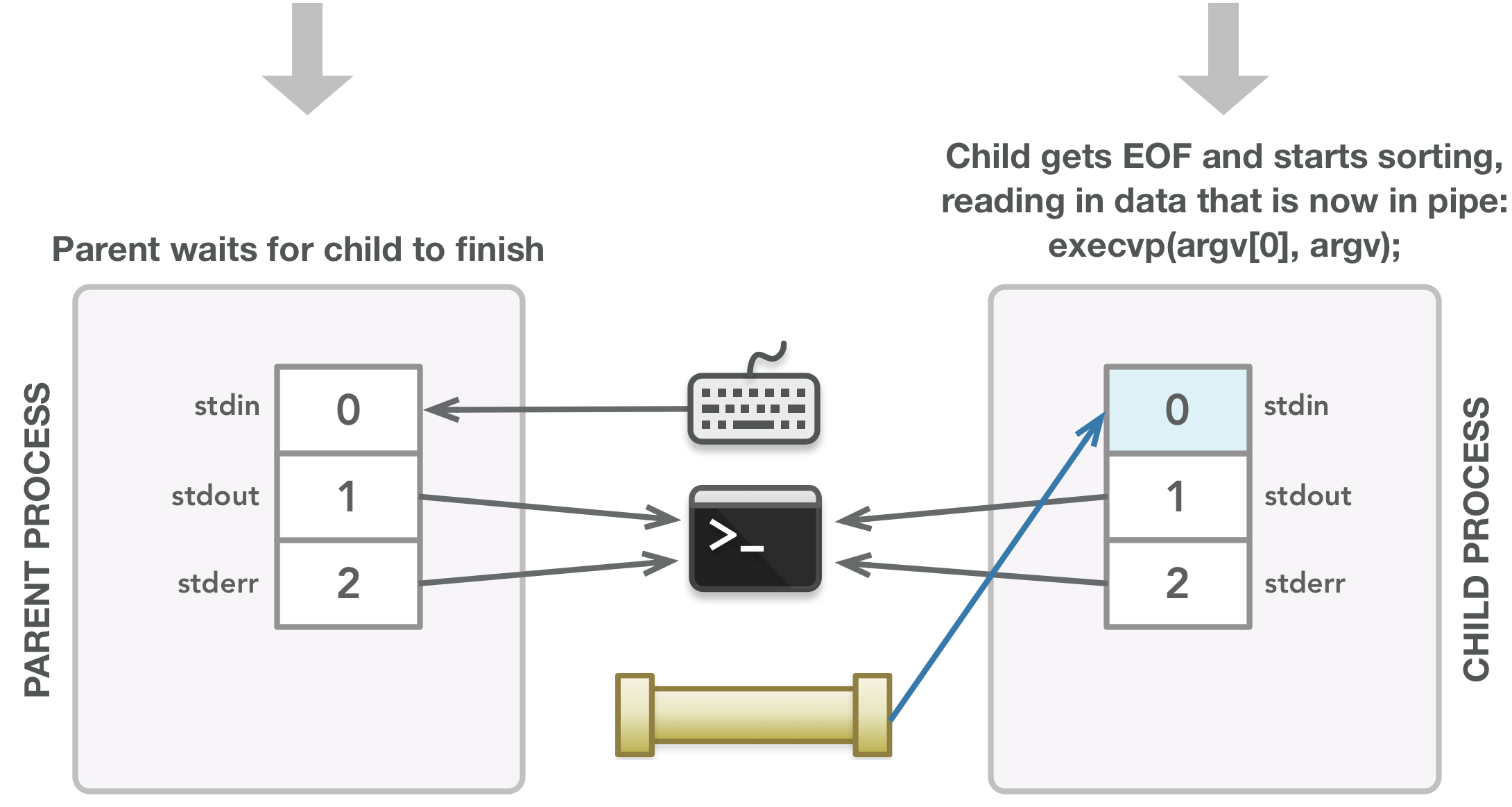
子进程基于输入执行sort命令。
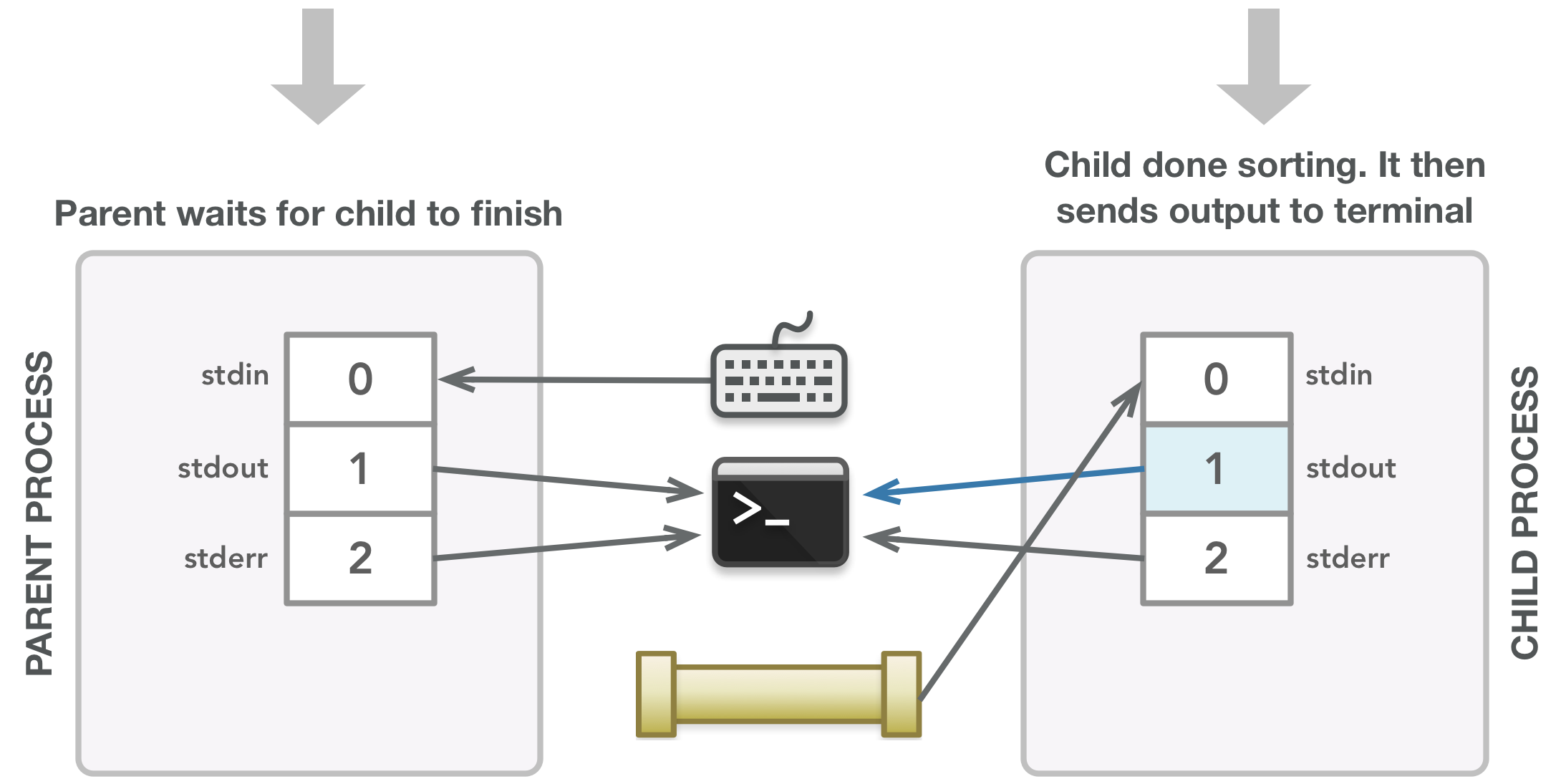
排序的输出被发送到终端,子进程终止时发送信号,然后允许父进程完成。
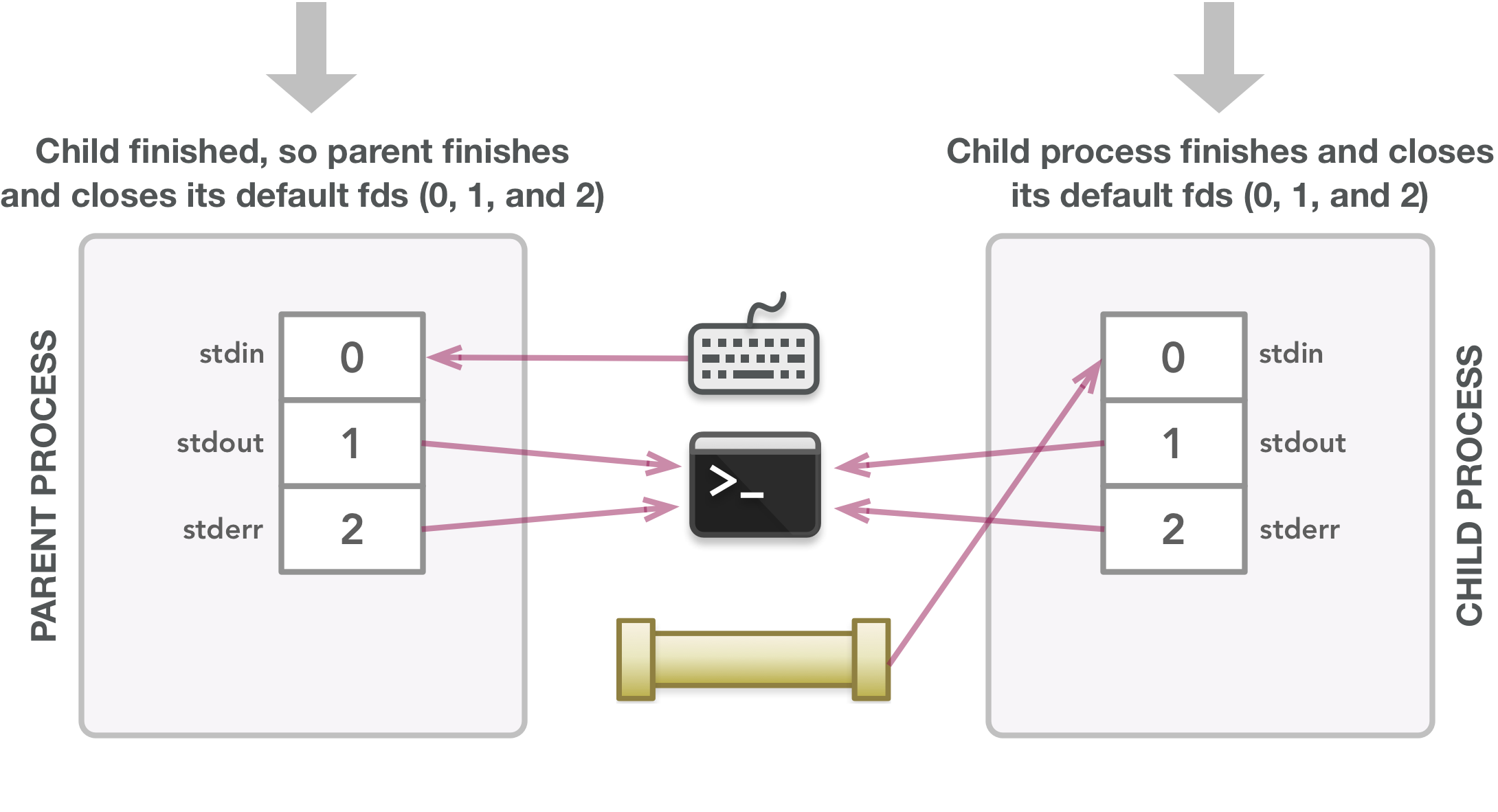
这些进程在自己的默认文件描述符之后进行清理。 程序执行期间使用的所有其他文件描述符都已正确关闭。
特别是,请查看具有蓝线的步骤,这些蓝线代表该时间点的数据流。 如果将这些步骤链接在一起,则会得到以下内容:父进程将数据写入管道的可写端,然后子进程通过其stdin文件描述符从管道的可读端读取数据,最后,运行结果作为输出从子进程发送到终端。 简而言之,图中的所有其他行最终都会将数据传递给其他人,甚至不会被使用。 此外,当程序结束时,需要关闭的文件描述符也消失了。 这是一个小程序示例,但您可以看到在涉及管道时它会变得多么混乱。 然而,这是一个美好的过程:跟踪数据并在自己之后进行清理,混乱最终会自行解决!
你会注意到的一件事是管道开始的文件描述符可能会根据需要重定向到另一个流。 管道是一种便利,它为您提供了两个设置为一起工作的文件描述符,但可以根据需要重定向它们的目的,以确保数据流入和流出正确的位置。
希望这些图表阐明在创建运行命令的进程时会发生什么。 重要的是不仅要了解文件描述符的使用方式,还要了解它们何时不被使用,以便可以适当地关闭它们。 他们很强大,很容易出错或留下。
输入输出重定向 - I/O Redirection
还有一个我想要讨论的话题。在我们迄今为止的讨论中,我们已经探索了使用三个默认文件描述符所带来的默认行为,其中我们分别使用键盘和终端来进行所有初始输入和最终输出。我们还研究了如何在管道中的进程之间传递数据。如果我们想要将现有文件用作管道中第一个命令的输入而不是使用键盘进行输入,或者如果我们想将最后一个管道命令的输出发送到文件,该怎么办?这可以通过I / O重定向完成。在命令行中,“<”字符用于输入重定向,“>”用于输出重定向,如果输出文件不存在则创建输出文件,如果输出文件已存在则覆盖。要将数据附加到输出文件而不是覆盖内容,可以使用“>>”。让我们看一个使用输入和输出重定向的示例。假设我们有文件words.txt,其中包含以下内容:
|
|
我们可以使用此文件作为sort命令的输入,然后将内容输出到另一个文件(如果需要,甚至是同一个文件),如下所示:
|
|
请注意,屏幕没有输出,因为输出存储在words2.txt中。 我们也可以将此命令编写为sort <words.txt> words2.txt。 如果我们使用cat打印输出文件的内容,我们得到以下内容:
|
|
事实证明,实现I / O重定向相对简单。 我们可以简单地使用前面看到的dup2()魔法:
|
|
希望这段代码非常简单明了。 如果有重定向的输入(其检测在此处未显示的另一个函数中处理),则在文件上调用open()并将该数据流分配给open()使用的文件描述符。 然后使用dup2()允许stdin读取该文件的内容作为输入。 同样,如果输出重定向位于管道的末尾,则重定向stdout以将最后一个命令的内容写入指定的文件。
这是一个代表前一个例子的图表:
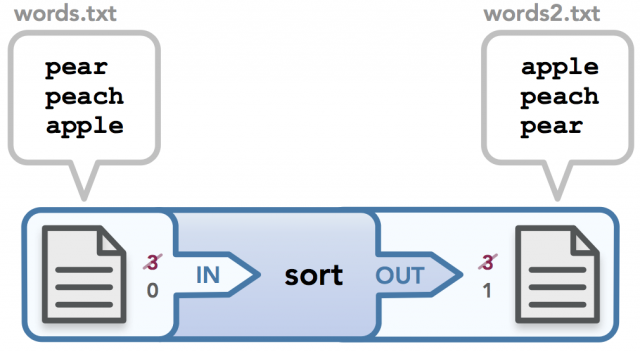
输入输出重定向
您可能想知道为什么文件描述符都以3开始。我在为家庭作业分配的迷你shell中运行此命令,因此我能够打印出运行任何命令时分配的文件描述符。 我的shell使用上面显示的代码。 请注意,首先我检查是否有输入重定向。 如果有,我调用open()命令来读取数据,该数据将此流分配给文件描述符3.一旦我重定向stdin来处理3处理的数据,然后我关闭3,这使得3可用于输出重定向 校验。 因此,两个文件都使用3开始,然后适当地重定向到需要数据的流,如红色穿透文本所示。
您可以在这里看到Unix的强大功能,我们不仅可以将小程序链接在一起制作更大的程序,而且我们还可以将数据加载到管道中并将数据输出到文件中以供将来使用。 我觉得这一切都太神奇了。:)
总结 - Summary
为了总结我们讨论过的内容,让我们看一个冗长的管道,其中包含一个简单但可能有用的示例。 让我们想象一下,你想要找出一群人中最喜欢的颜色。 有人键入一个颜色列表,其中每一行代表一个人最喜欢的颜色。 你的工作是获取该文件并在其上运行一些命令,理想情况是在一个令人印象深刻的管道中,这样三种最流行的颜色都保存在一个新文件中,并计算每种颜色收到的票数。 这是你如何做到的:
|
|
图示如下:
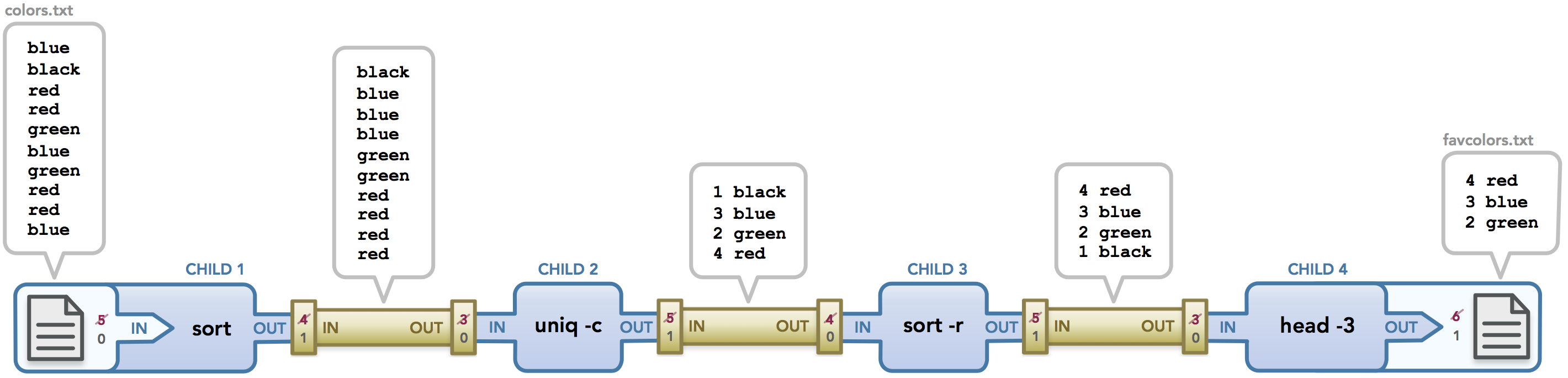
寻找最受欢迎的颜色
命令的工作方式如下:colors.txt包含以随机顺序输入的颜色列表。 uniq命令删除与其前面的行相同的任何行,从而有效地删除所有连续的重复行。 为了使其按需工作,我们需要先对颜色列表进行排序,这就是我们先调用sort的原因。 然后我们调用uniq -c,其中-c选项将删除重复的颜色,并显示每种颜色出现的次数。 接下来,我们按降序对这些数据进行排序(这是-r选项在传递给sort时的作用)。 最后,我们调用head-3来获得结果中的前三行,并将该输出存储在favcolors.txt中。 最后,favcolors.txt具有以下所需数据:
|
|
这比我们研究的其他示例更复杂,图中显示的文件描述符清楚地表明了这一点。 因为我的shell程序在检查I / O重定向之前调用pipe(),所以第一个管道获取文件描述符3和4,然后输入和输出文件的文件描述符分别被分配5和6。 一旦5和6分别重定向到stdin和stdout,它们就会被关闭(如图中最左侧和最右侧所示)。 在创建第二个管道时,它可以使用一些回收的文件描述符,最后一个管道也是如此。 不要太担心文件描述符是如何被回收的,因为这是我的代码所特有的,但是知道最后一切都被清理干净并且数据被正确传递出去。
我们已经介绍了相当多的材料,虽然我喜欢我的观众,但我真的为了自己的理智而写了更多内容! 但一如既往,我希望这是有帮助的。 写下这一切并创建图表肯定巩固了我对一切的理解,尽管对于我上周经历的期中和家庭作业噩梦来说可能已经太迟了一周。:)
一个特别的“谢谢!”走向Hemanth,这位赛事助理回答了我关于这些主题的无数问题! 我非常擅长确保它们既准确又清晰,并且真正帮助我获得了一个可靠的理解点。 这个班级的比赛工作人员一直很棒,但Hemanth真的已经超越了我的帮助。 杰瑞教授也是如此,他容忍了我的许多问题和对我的比赛表现的恐慌。 :) Shoutout阅读这篇文章的准确性。 我非常喜欢斯坦福大学。
谢谢你的阅读!